当我们某些表出现重复数据的时候,会影响到统计,这是这时候需要表引擎ReplacingMergeTree实现去重,用pt_order_num作为去重字段,可以加入在查询的时候加入final关键字来实现去重,创建一个log_test_merge表
CREATE TABLE log_test_merge
(
id Int64,
uid Int64,
pt_order_num String
) ENGINE = ReplacingMergeTree()
ORDER BY pt_order_num 插入一些数据
INSERT INTO log_test_merge (id, uid, pt_order_num)
VALUES
(1, 2, '7777'),
(1, 2, '7777'),
(1, 2, '8888'),
(1, 2, '8888'),
(1, 2, '9999'),
(1, 2, '9999'), 执行不带final的查询
SELECT * FROM log_test_merge; 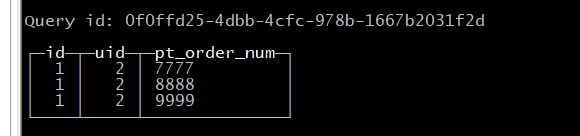
发现结果,并不是预想的结果,明明插入了六个记录,出来只有三个,这是为什么呢,实际上是因为ReplacingMergeTree表引擎在你插入过程中,如果存在重复数据的情况下,会自动去重。
继续执行上面的插入,然后继续查询
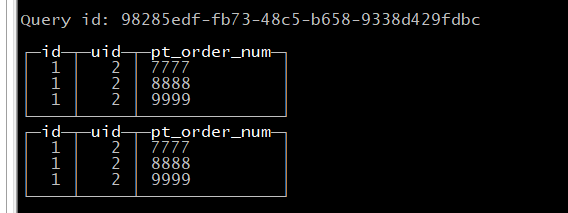
这个时候,为什么第二次的插入的时候,库里面存在有记录,为什么没去重的,原因是ReplacingMergeTree表引擎数据的去重只会在数据合并期间进行,合并会在后台一个不确定的时间进行。所以如果想要去重,要不就等clickhouse处理完,要不就候查询的时候要加入FINAL关键字。
SELECT * FROM log_test_merge FINAL; 
当然,还有一个办法,就是优化表,调用OPTIMIZE语句,强行合并,数据重组。
OPTIMIZE TABLE log_test_merge FINAL 在执行查询
SELECT * FROM log_test_merge; 
数据已经被合并了,但是要谨慎使用OPTIMIZE,因为会引发大量的数据读写,所以一般需要找个时间合并数据即可。

发表评论